
Предисловие
В статье пойдёт речь о создании LoRA под Checkpoint на базе FLUX для средневекового и фэнтезийного оружия ближнего боя, а так же сравнении этой LoRA с другими созданными ранее на базе Illustrious и Pony.
Упор будет сделан на ознакомление с параметрами обучения LoRA, а так же сравнение результатов с примерами, полученными в различных условиях. Мы пошагово пройдёмся по всем этапам создания своей LoRA и постараемся найти ответы на вопросы, которые часто беспокоят новичков, во избежание подводных камней.
Вступление
Итак, Вы решили создать свою LoRA (Low-Rank Adaptation), как можно судить из названия, LoRA позволяет адаптировать модель под нашу конкретную задачу, сохраняя большую её часть данных неизменными. Проще говоря, с помощью LoRA мы показываем нейросети как должны выглядеть те или иные аспекты изображения, будь то выбранный стиль, наличие третьего глаза у существа, эффект светящейся кожи или внешний вид персонажа с разных ракурсов.
Нам не нужно обучать нейросеть всем возможным позам, тому как выглядят предметы, объяснять значения и явления, это всё уже заложено в базовой модели, но мы можем настроить LoRA таким образом, чтобы нейросеть создавала необходимый результат, схожий с нашим набором данных, выстраивая ассоциативную связь и подставляя LoRA в создаваемое на основе подсказок изображение.
Таким образом, мы можем научить базовую модель тому, что она не умела создавать ранее, или как в нашем случае, для получения одинаковых результатов генерации по названию средневекового оружия.
Хотелось привести небольшой пример использования LoRA персонажей.
Цель: создать сложное изображение с несколькими различающимися героями.
Основная сложность заключалась в размещении существ относительно друг друга и создании композиции. Было принято решение прибегнуть к хитрости. Благодаря хорошей семантике базовой модели SeaArt Film были описаны девушка, стоящая на балконе второго этажа с ракурсом из-за её спины вниз и существо, похожее на аксолотля, стоящее на том же балконе рядом. А позже описано парящее в воздухе маленькое существо, напоминающее девочку. Конечно, ни одно из существ не было похоже на искомых нами героев и для корректировки их облика были применены 2 разных LoRA, одного и другого персонажа по очереди. На картинке ниже вы можете увидеть постепенные изменения облика персонажа благодаря повышению силы LoRA за несколько итераций:
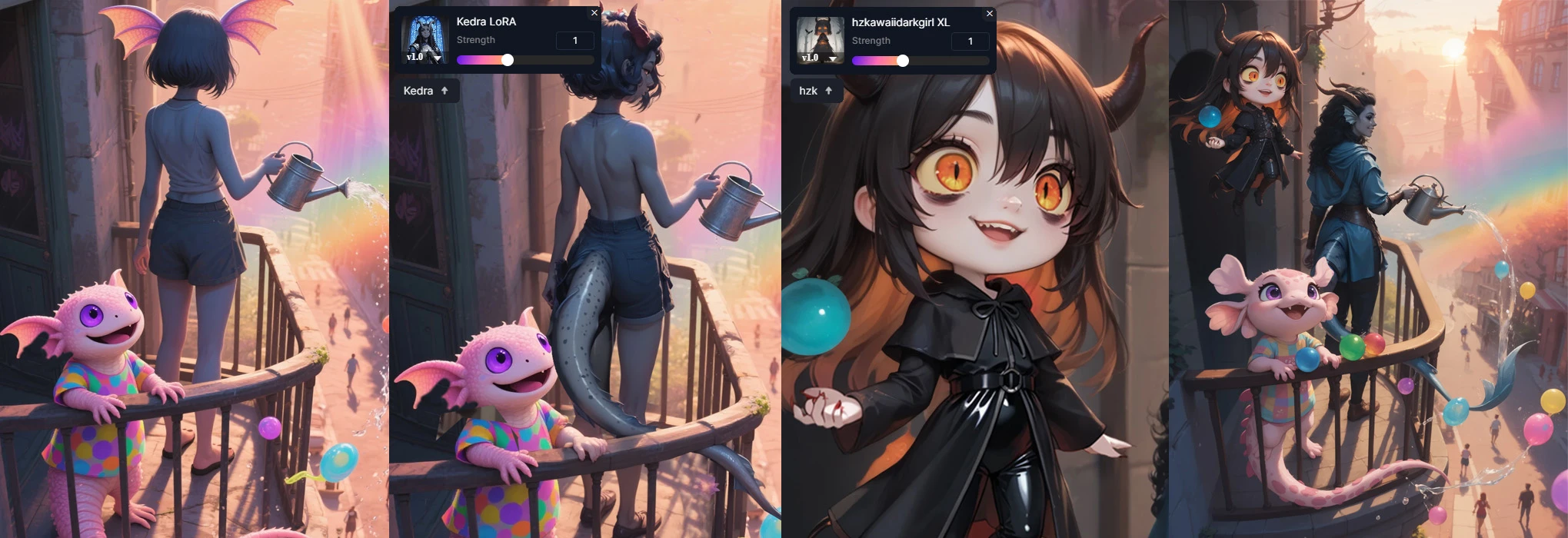
Выявляя ассоциативные связи, благодаря LoRA, нейросеть приближает сгенерированный результат к предоставленным нами данным. К примеру, во всех картинках, на которых была обучена LoRA персонажа у неё чёрный глаз, синяя кожа, рога на голове и плавники, когда мы применяем эту LoRA на изображении, то у всего, более менее похожего по форме на голову, проявляются подобные черты. При увеличении силы LoRA, они могут проявиться и на других объектах, в который нейросеть найдёт схожие черты:

Как мы видим на картинке выше, некоторые объекты при изменении изображения с включённой LoRA персонажа стали приобретать его характерные черты.
В случае нашего примера, целью является создание LoRA для средневекового и фэнтезийного оружия, чтобы всего за одно триггерное слово или описание, мы могли вложить в руку любого персонажа подобие того, что у нас будет в данных для обучения LoRA.
Но для начала нужно определиться с основой, на которую будет опираться наша модель.
Выбор базовой модели
В зависимости от Ваших предпочтений и задач, перед Вами встаёт вопрос о выборе между базовыми моделями, такими как: SD1.5, SDXL, FLUX, Ponu, Illustrious, SD3.5 и т.д.
У всех есть свои преимущества и компромиссы при обходе недостатков. Например, для составления подсказки на FLUX Вы можете использовать описания, наполненные деталями на понятном литературном языке, высокая семантика этой модели позволит распознать Вашу задумку и добиться сложного композиционного сходства в реализации идеи. Но обучение на FLUX сейчас несколько дороже, как и создание изображений, а разрешение ниже аналогов других базовых моделей. Модели же, базирующиеся на Pony могут чуть хуже интерпретировать подсказку, включающую более одного персонажа и их взаимодействие, зато превосходно подходят для демонстрации образов в различной стилистике и высоком разрешении.
Пример подсказки: На поверхности воды, зловещая темная чешуйчатая рыба поднимается из глубин, устремляясь со дна к поверхности, цветок лотоса на кувшинке, тёмное освещение, ощущение тьмы и опасности, колючий, яркая фантазия, мрачные зловещие оттенки.
Показал результаты у различных базовых моделей:

В случае первого Checkpoint на базе модели Pony, рыба и вовсе перестала быть собой, но приобрела узнаваемые отличительные особенности модели, нереалистичное окружение и формы, приятные глазу цвета и узнаваемые очертания, читаемость и отделение от фона основного объекта в композиции. В случае модели SeaArt-Infinity, просматриваются чёткие реалистичные текстуры и высокое соответствие поставленной в подсказке задаче. Несмотря на "примеси" LoRA, полагаю, многие узнают её стиль. В версии с FLUX просматриваются общие черты с Infinity, и не удивительно, ведь они основаны на одной базе FLUX, отличающейся высокой семантикой и стремлению к высокому числу деталей, в некоторых случаях - к реалистичным текстурам, если LoRA не задаёт иной стиль. Для IIlustrious просматриваются характерные черты и стиль, свойственный цифровым изображениям, семантика и понимание задачи остаётся на высоком уровне, но зачастую, как мне показалось, требует использования подходящих LoRA для сложных сюжетов и понимания картины. Модель SD XL (Stable Diffusion), несмотря на разнообразие стилей и хорошее понимание запросов, не всегда хорошо справляется с генерацией сложных предметов (эту проблему частично может помочь решить использование LoRA), а так же, иногда плохая фотореалистичность.
Опробуйте различные модели, чтобы определиться с Checkpoint для Вашей LoRA.
Теперь мы должны подготовить данные для обучения LoRA, желательно, в стиле нашего выбранного Checkpoint, именно по этому мы вначале определялись с ним.
Подготовка данных для обучения
Общее количество изображений, необходимых для обучения зависит от сложности и особенностей нашей задумки, например, для того, чтобы LoRA точно воспроизводила облик нашего персонажа, желательно собрать около 25-40 его изображений, желательно, одного стиля, но с разных ракурсов. Можно использовать изображения сгенерированные самой нейросетью.
Среди которых ~12 качественных портретных снимков, 6 в полуоборота, 4 сзади. 8 Снимков в полный рост, 6 поз сидя. Делайте изображения с разными эмоциями и в разной одеждой, если вы не хотите, чтобы она "приклеилась" к образу персонажа. Так же и с фоном, старайтесь менять его от изображения к изображению. Старайтесь не использовать тёмные (как нечитаемые, недоэкспонированные) или слишком сложные фоны, если в этом нет необходимости. Важно избегать некачественных изображений, иногда лучше отказаться от нескольких работ с браком, чем включать их в LoRA и потом исправлять ошибки в готовых результатах.
При создании LoRA для стиля, постарайтесь подготовить различные предметы, выполненные в нужном Вам оформлении, а так же людей под разными углами с различными видами и в разной одежде, 8-14 изображений. Дополните это сценами без какого-либо основного предмета, хотя бы несколько различающихся между собой.
Например, для создания LoRA персонажа, мной были использованы 47 изображений:
18 - в полный рост
25 - это портреты
7 - сидя
6 - в полуоборота
6 - спиной
5 - с нижнего ракурса
10 - с верхнего ракурса
(47 в сумме, но некоторые снизу и со спины, например, некоторые в полный рост и сидя и т.д.)

А для создания LoRA для фона и локаций использовались в общей сложности 83 изображения:

Изображения для той и другой LoRA, предварительно прошли обработку и были приведены к одному стилю. А именно, персонаж всюду получил свои характерные черты: чёрный глаз, плавники, рога, цвет кожи, хвост, где-то через редактирование в редакторе и последующее изменение через Checkpoint на базе которого, в дальнейшем, проходило обучение LoRA. Изображения для LoRA локаций и фона были созданы в высоком качестве а, затем изменены с теми же подсказками через Checkpoint на котором будет проходить обучение.

Если говорить про создание LoRA для сложных технических деталей или абстрактных концепций, то может потребоваться больше данных для обучения, 50-100 качественных изображений.
Для нашей LoRA с оружием мы подготовили и затем обобрали всего 22 изображения, где на каждом с помощью генерации с последующим редактированием разместили нужное нам оружие:

Характерными чертами для кистеня на цепи или моргенштерна на цепи является увесистое стальное ядро, прикованное подвижной цепью к короткой деревянной палке, зачастую, удерживаемой одной рукой.
В нашем случае, мы создаём личное оружие определённого персонажа, по этой причине оно везде выглядит одинаково. В некоторых случаях, зачастую, лучше разнообразить пул наших данных для обучения, дополнив крупными планами, при другом освещении и ракурсе, например: крупным планом в руке.
Настройка параметров обучения
После загрузки, изображения были центрированы в разрешении 1024x1024px. и благодаря алгоритму маркировки: jou2, он очень похож на BLIP (систему, напоминающую естественный язык, который неплохо подходит под Flux и SD3.5) с минимальными изменениями и удалением лишнего.
Из-за низкого значения порога тегирования, текст получился длинным, описывающим некоторые мелочи.
Так же, ко всем изображениям было автоматически добавлено триггерное слово: MBrush, но после удалено с тех, где на было данного оружия: кистеня на цепи, прикреплённой к деревянной палке.
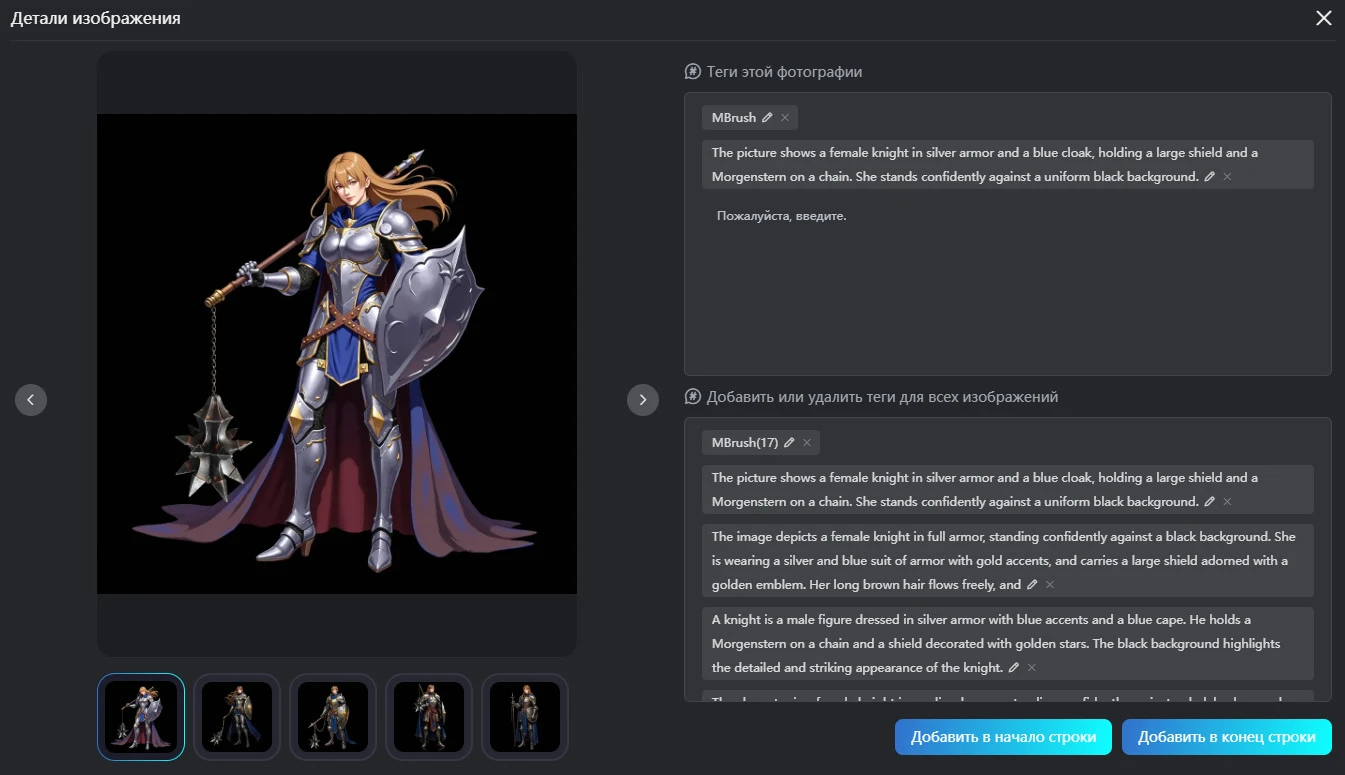
Если в случае с LoRA для персонажа со всех облаков тегов для каждого изображения были убраны её характерные черты в виде: цвета кожи, рогов, плавников, глаза и хвоста, т.е. того, что не меняется от изображения к изображению, то в нашем случае с оружием, краткое описание было оставлено, ведь пользователь будет создавать с ним своих персонаже в своих сюжетах.
Пример:
Девушка с русыми распущенными длинными волосами в серебряных узорных доспехах с синим плащом за спиной удерживая в руке щит стоит в полный рост с моргенштерном на цепи на полностью чёрном фоне.
В случае, если бы мы выбрали метод: Deepbooru. мы бы получили набор тезисов, определяющих те или иные аспекты изображения:
Чёрный фон, 1девушка, оружие, синий плащ, серебряный доспех, герб, тело целиком, полный рост, жёлтые волосы и т.д.
Они могут быть проще к редактированию и позволяют уместить большой объём данных, хорошо подходят для моделей основанных на основе SD1.5, Pony и т.п.
С самым сложным разобрались, теперь переходим к тонкой настройке.
Количество шагов было выставлено на 1232 (22 изображения)
При 7 повторениях (Repeat) и 8 циклах (Epoch)
Этого должно хватить для FLUX (да и по энергии дешевле). "Пережаренные" LoRA, которые слишком сильно переобучены, тоже не хорошо. Чрезмерные повторения могут привести к жесткости изображения.
Mixed precision был установлен на bf16 (Brain Float 16) - это позволит сэкономить память и работать быстрее.
Gradient Checkpointing был отключён. При активации техники, он сохраняет только ключевые промежуточные состояния (checkpoints) в процессе прямого распространения. Во время обратного распространения, когда необходимо вычислить градиенты для обновления весов, система восстанавливает необходимые активации, вычисляя их заново из ближайших сохранённых точек.
Enable Bucket - автоматически классифицирует разрешение изображений, у нас все изображения квадратные с соотношением сторон 1024x1024px.
Bucket Reso Steps - он указывает количество шагов, которые система применяет для группировки изображений с похожими разрешениями (бэкетирования). Было оставлено 64 шага.
Min и Max Bucket Reso - при настройке модели масштаб набора данных автоматически увеличивается. Это позволяет подготовить набор данных с разным разрешением, и LoRA будет автоматически увеличивать масштаб до указанного значения. От 256 до 1024 px.
Color Aug - используется для увеличения разнообразия цветовых вариаций в обучающих изображениях. Это позволяет искусственно увеличить количество типов изображений в датасете, что, в свою очередь, помогает модели обобщать различные цветовые вариации и улучшить способность модели создавать изображения с разным цветовым тоном.
Flip Aug - позволяет улучшить производительность моделей машинного обучения, обученных на данных временных рядов, за счёт уменьшения переобучения и улучшения обобщения.
Была составлена подсказка для генерации простого изображения при демонстрации.
Скорость обучения была задана: 0,0001
Скорость обучения меняют, чтобы настроить процесс адаптации модели под конкретные задачи. Это важно, так как LoRA позволяет обучать только небольшое количество параметров, оставляя базовую модель неизменной, и выбор подходящей скорости обучения влияет на эффективность адаптации.
Высокая скорость обучения - ускоряет начальную сходимость, но может привести к нестабильности обучения или невозможности найти оптимальный минимум.
Низкая скорость обучения - обеспечивает более стабильную и точную тренировку, но может требовать больше эпох для сходимости, увеличивая общее время обучения.
Можно использовать динамические планировщики скорости обучения или поэкспериментировать самостоятельно.
Оптимизатор был выбран: AdamW8bit (квантизованный оптимизатор AdamW) имеет преимущества, связанные с уменьшением использования памяти.
Количество перезапусков: не менялся - 1. (LR Scheduler Num Cycles) и указывает на количество раз, когда скорость обучения перезапускается во время тренировки. Это побуждают модель исследовать разнообразные решения, периодически сбрасывая скорость обучения.
Train U-Net Only - оставлен включённым, он который обновляет только компонент U-Net модели во время обучения для фокусировки ресурсов на улучшении желаемых результатов без ненужных вычислений, так как U-Net — ключевой компонент для задач, например, сегментации изображений или извлечения признаков.
Настройки сети:
Network Rank Dim - это параметр, который определяет размер низкоранговых матриц для линейных слоёв. Он связан с сложностью и способностью модели, влияет на способность сети изучать сложные паттерны.
Регулировка сложности модели: Высокое значение даёт большую выразительную мощность, но повышает риск переобучения. А низкое значение подходит для простых моделей и понижает риск переобучения, но потенциально недостаточно для сложных задач.
Другие параметры были выбраны по умолчанию.
Результат после обучения LoRA
Модель завершила своё обучение и была опубликована. Выбрана последняя 8-ая LoRA как наиболее соответствующая ожиданиям.

Checkpoint FLUX позволяет, при прочих равных, генерировать изображения в разрешении 1024x1024px. вплоть до 60 шагов.
Высокая семантика, в теории, позволит добавлять LoRA при формировании сложных батальных сцен, но из-за малого количества данных для обучения с малым количеством повторов - результат может быть не постоянен, но и не должен сильно влиять на внешний вид персонажа.
Давайте взглянем на сгенерированный результат при силе 1. (С добавлением LoRA персонажа и LoRA для увеличения числа деталей):

Изображение 1. Изображение 2. Изображение 3.
Если проводить работу над ошибками, то стоило сделать крупные планы оружия в руке отдельно, хотя бы несколько штук. Использовать стиль попроще и разнообразить персонажей, держащих оружие в руке, захватывающими различные динамические позы.
Сравнение получившихся моделей
Пришло время сравнить результаты.
Для Kedra LoRA на базе IIlustrious
Repeat: 12
Epoch: 16
Total number of steps: 9000
Подходили значения:
sampler:Euler a
steps:35
cfg_scale:4.0

Где первые 3 были сгенерированы с нуля, а последние 3 были изменены с помощью LoRA на подготовленных изображениях.
Для Fantasy backgrounds на базе IIlustrious
Repeat: 10
Epoch: 10
Total number of steps: 8300
Подходили значения:
sampler:Euler a
Strength: ~0.7-1.0
Sampling Steps: 32
CFG Scale: 4.0
Clip Skip: 2

Получились приятные цвета и хорошо сочеталась со многими Checkpoint, не только с тем на котором обучалась (MiaoMiao Harem).
1 картинка - MiaoMiao Harem, 2 и 3-и картинки - GR-Illustrious 3in1.
Иногда возникали ошибки с "левитирующими" горами или деревьями (4ая картинка) или обилием объектов как на 5-ой.
А так же с LoRA персонажей (была проверена с Kedra LoRA и другими LoRA персонажей, участвующими в конкурсе).
Для Diana by E5CKAR на базе FLUX
Repeat: 4
Epoch: 11
Общее количество шагов: 1100
Подходили значения:
sampler:Euler a
Strength: 1.0
Sampling Steps: 60
Модель часто использовалась совместно с созданной и описанной в статье, по этому предлагаю рассмотреть их вместе для последующего сравнения.
Модель LoRA brush on a chain на базе FLUX
Repeat 7
Epoch 8
Общее количество шагов: 1232
Нужно было ставить силу выше, для видимых результатов:
sampler:DPM++ 2S a Karras (использовался и Euler a)
Euler a - давал более чёткий, но мультяшный рисунок, а DPM++ 2S a Karras немного добавлял шумов, но становилось чуть больше деталей изображения.
Strength: 1.35-1.65
Sampling Steps: 60

Выборка была минимальная, взяты, буквально, первые сгенерированные изображения.
На первом и втором портрете использовалась только модель Diana by E5CKAR, так же, именно из неё были сгенерированы данные для обучения LoRA brush on a chain которая сгенерировала 3-е изображение совместно с первой моделью и 4-ое уже без неё.
В последнем изображении использовалась LoRA для деталей 1,2,3, с малым значением силы: 0.15.-0.60 при значении силы LoRA brush on a chain Strength : 1.55. Во втором изображении последнем был выбран sampler: DPM++ 2S a Karras.
Среди ошибок можно заметить наше оружие у двух воинов в кадре, и более того, даже свисающим с дерева. Давайте сгенерируем ещё 3 примера:

Параметры не изменилась, участвовали 3 LoRA с деталями (1,2,3) и Diana by E5CKAR Strength : 0.15, sampler:DPM++ 2S a Karras. LoRA brush on a chain Strength : 1.55. Было высокое значение силы, из-за чего нейросеть посчитала, что нам очень нужен кистень в качестве молота, котелка, колокольчика на входе в кузню :-) Но общий результат для первой попытки показался удовлетворительным.
Благодарим за просмотр и желаем Вам удачи, 🍀.
Используемые ресурсы
Для создания моделей был использован персонаж авторства - E5CKAR
В первом примере использовалась модель - hzkawaiidarkgirl XL Авторства - Uyciak
При подготовке обучающего материала использовались статьи:
- Официальное Обучение LoRA
- LoRA training parameters с https://github.com.
- Understanding Learning Rate in LoRA Training
- Обучение модели с помощью LoRA (версия для десктопа). На примере датасета полученного из самой нейронки.
- Understanding Min SNR Gamma, Network Rank Dim, and Tokens in LoRA Training
При составлении примеров и формировании LoRA использовались модели:
- SeaArt Film
- Fantasy backgrounds
- Kedra LoRA
- Diana by E5CKAR
- LoRA brush on a chain
- А так же Checkpoint FLUX.




