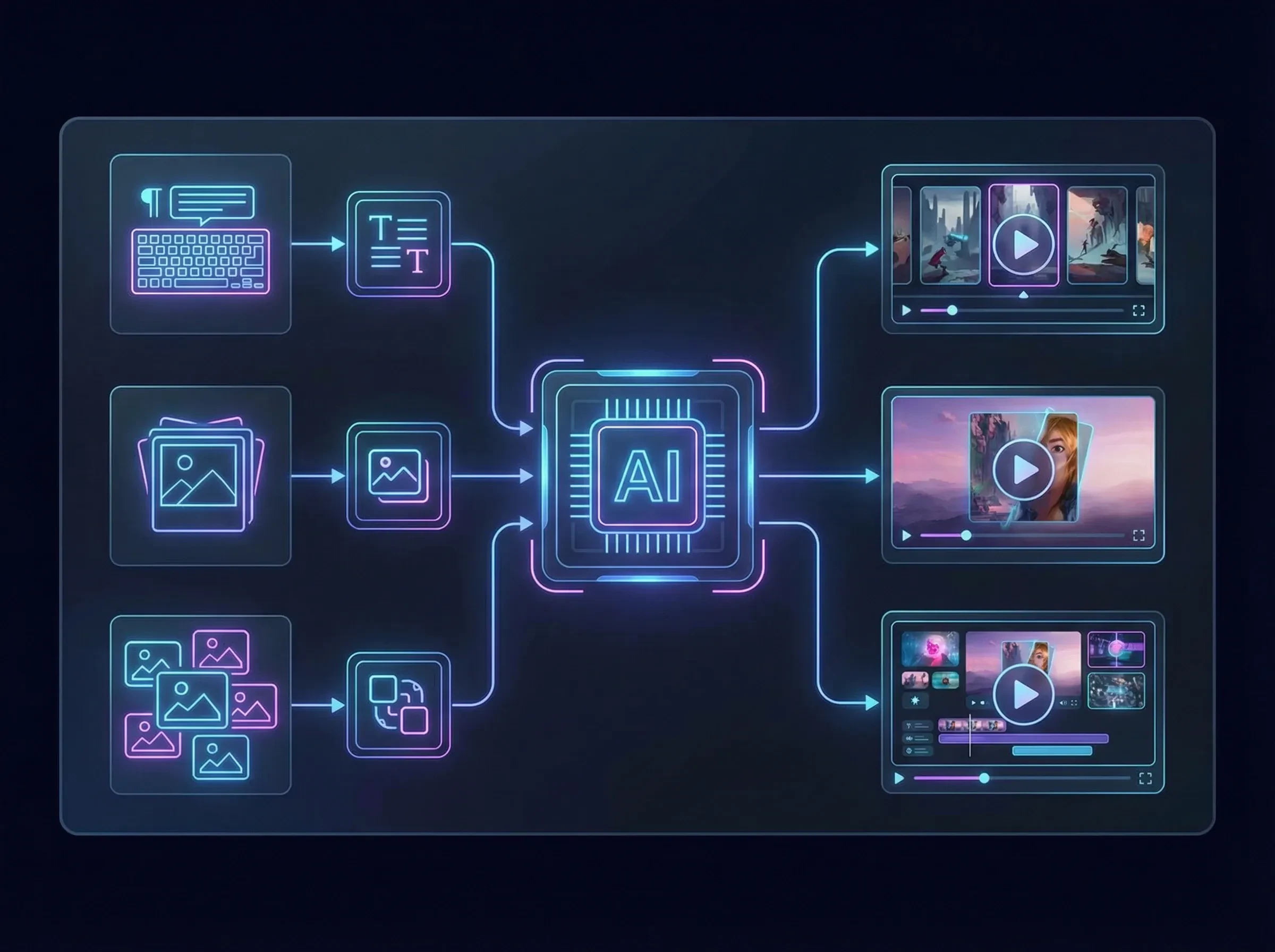
Inizia a creare
Cronologia
Creazione Privata
Dettagli
2.2K
1.1K
2025-12-30 13:30:30 Aggiorna

Nessun dato disponibile

SeaArt Comfy Helper
339
5.5K
Explore Related










Scarica l'app SeaArt
Continua il tuo viaggio di creazione AI su mobile