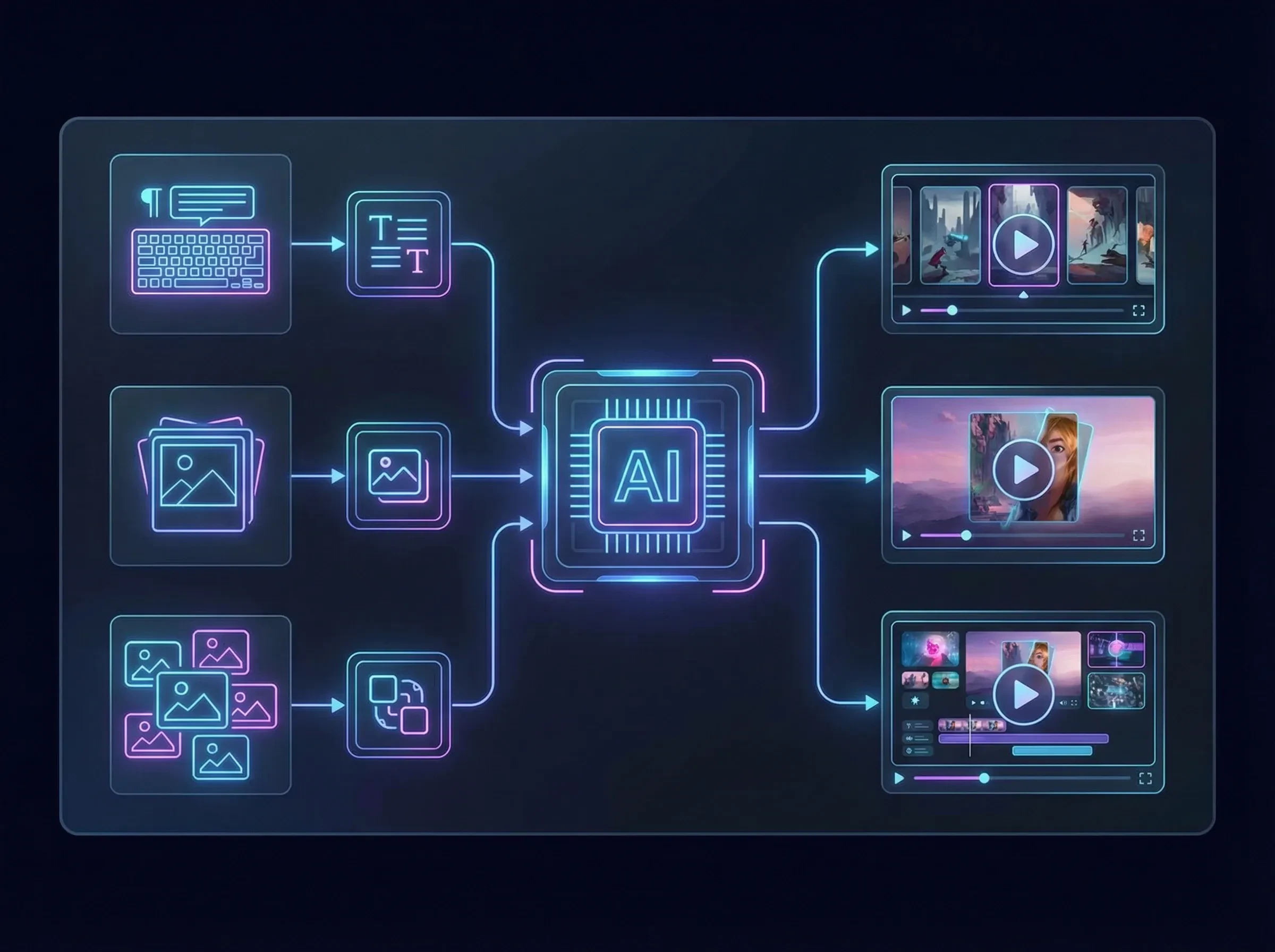
What kind of content is multi-image reference generation suitable for?
Suitable for feeding the model elements like 'logos/product images/scene mood images' together to quickly get a first draft of an ad short film, opening atmosphere, or product showcase video with unified visuals.