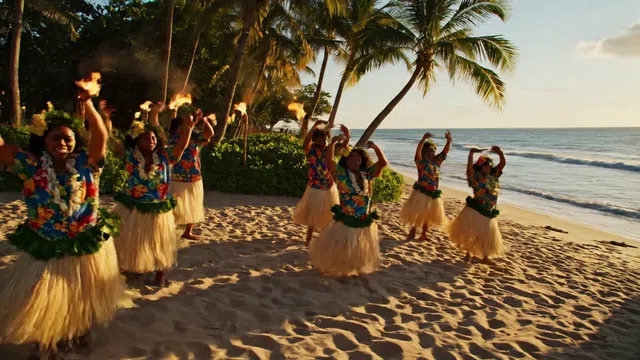まだ十分な評価やレビューが集まっていません
テキストまたは画像を起点に生成でき、3枚までの画像コンポジション、開始フレームと終了フレーム間の自動トランジションに対応。プロンプトへの追従性とネイティブな効果音体験を強化。
最大3枚の画像組み合わせと Frames-to-Video(開始フレームから終了フレームへのトランジション)に対応し、製品ハイライト映像やブランド短編に最適。
画角・スタイル・ストーリー指示の理解精度が向上し、テーマ逸脱を抑制。実用版に向けた反復改善により適しています。
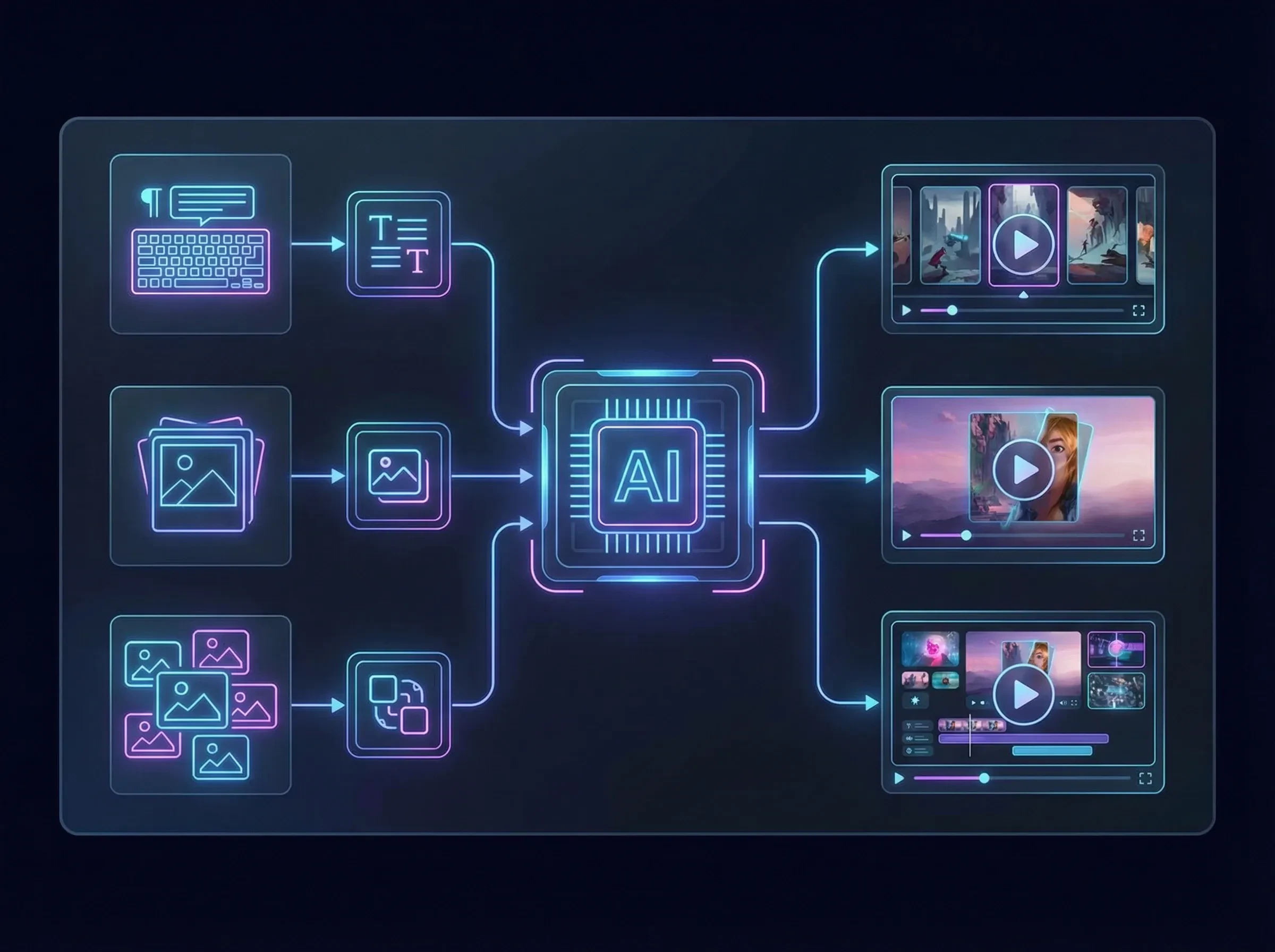
テキストから動画、参照画像を用いた画像から動画の双方に対応。複数画像のコンポジション生成をサポートし、ブランド要素の統合やシリーズコンテンツ制作に最適。
パラメーター設定
必要な機能に応じて接続します(テキスト & 画像 & 参照生成)。
プロンプト入力
ノードの入力欄に、望むシーンを入力します。
結果を生成
Generate ボタンをクリックし、少し待つと生成結果が表示されます。
実用的な結果を得やすくするため、プロンプトはどのように書けばよいですか?
「シーンの被写体+動作/イベント+カメラ言語(画角/カメラワーク)+スタイル/画質+雰囲気/ライティング+尺/アスペクト比(選択肢がある場合)」という構成を用い、主要な制約条件を一貫させてください。
複数画像参照生成は、どのようなコンテンツに適していますか?
ロゴ・製品画像・シーンのムード画像などの要素をまとめてモデルに与えることで、ビジュアルを統一した広告短編、オープニングの雰囲気映像、製品紹介動画の初稿を素早く得る用途に適しています。