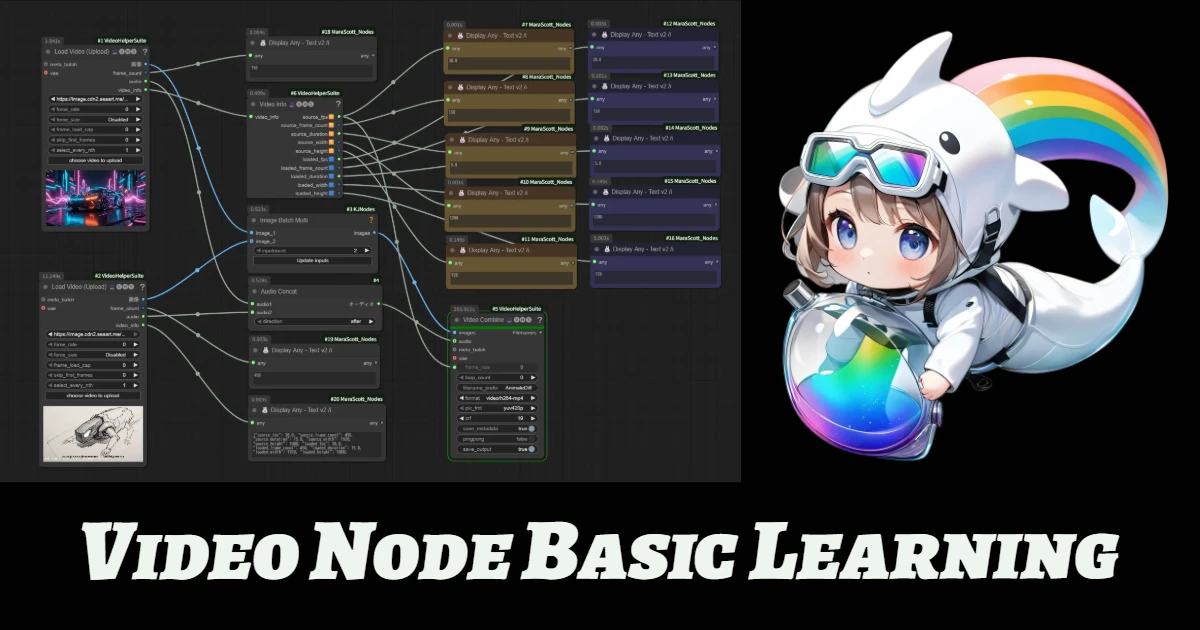
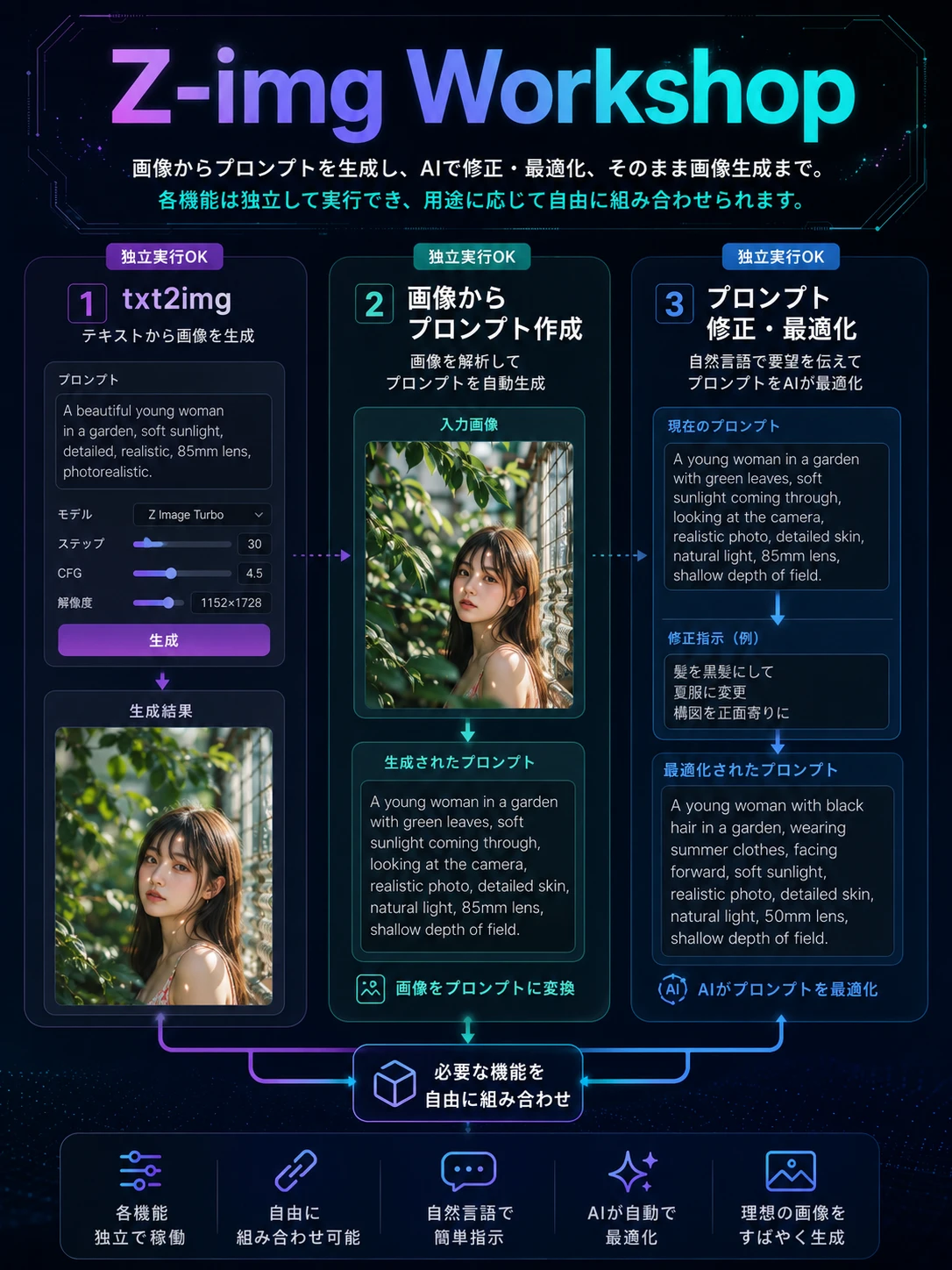
Anima model user Anime Character Scene Generator This workflow generates high-quality anime-style illustrations of muscular characters with customizable poses, outfits, and urban backgrounds. Ideal for character design and creative poster creation. Cartoon title + character name + costume + pose + sceneExp.1.shiranui mai, fatal fury, 1girl, brown eyes, brown hair, long hair, ponytail, high ponytail, japanese clothes, ninja2.magical mirai miku (2017), magical mirai (vocaloid), 1girl, aqua eyes, hair between eyes, blue eyes, aqua hair, very long hair, blue hair, twintails, black skirt, detached sleeves3.raoh (hokuto no ken), hokuto no ken, 1boy, manly, muscular4.cell (dragon ball), dragon ball, 1boy5.son goku, dragon ball, 1boy, spiked hair, black hair, blonde hair, muscular male, dougi, wristband3.alcina dimitrescu, resident evil, 1girl, mature female, pale skin, red lips, yellow eyes, black hair, short hair, sun hat, white dress, black gloves, black headwear, pearl necklace, earrings, lipstick7.morrigan aensland, vampire (game), 1girl, demon girl, green eyes, long hair, green hair, leotard, head wings, bat wings, purple wings, bridal gauntletsPrompt For example, go to... >