








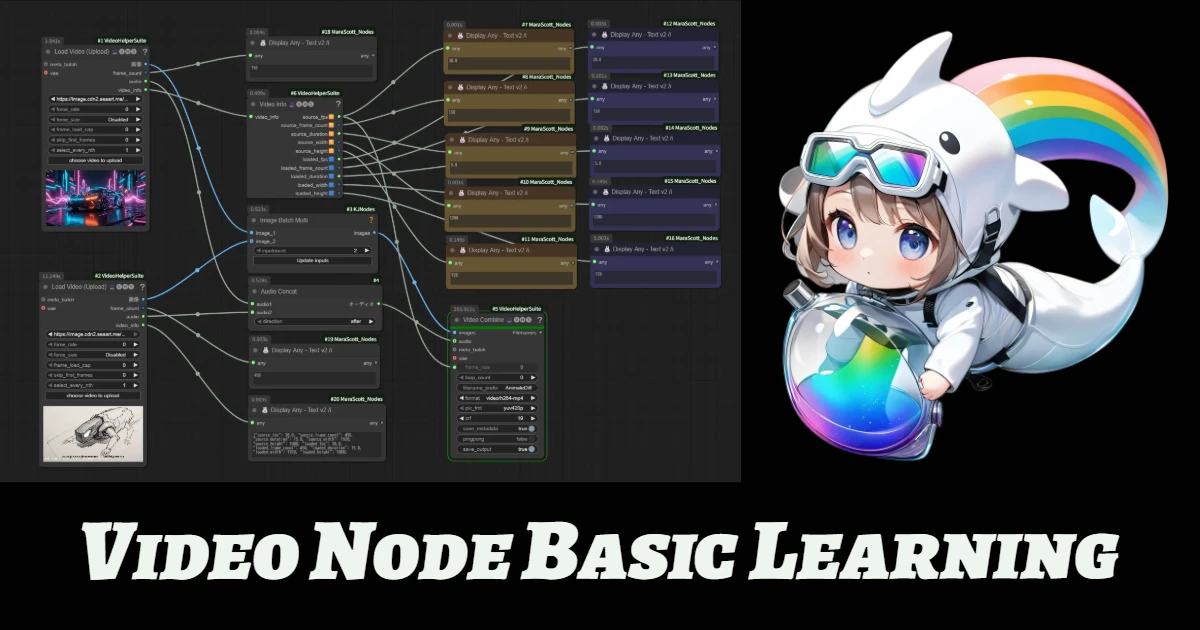










































Benvenuto in SeaArt AI Workflow
Semplifica il tuo processo creativo con i workflow del generatore di arte IA di SeaArt, progettati per soddisfare le diverse esigenze di artisti, designer e creativi. Da immagini IA a video IA, SeaArt AI offre tutto ciò di cui hai bisogno per dare vita alla tua visione artistica.




Perché utilizzare il ComfyUI Workflow su SeaArt AI?


Interfaccia Semplice
SeaArt AI offre un'interfaccia intuitiva che rende facile configurare i workflow. Tutti i workflow sono progettati per tutti, anche se non hai competenze di programmazione.
Workflow Personalizzabili
Progetta il tuo workflow a modo tuo. Dalla formazione avanzata LoRA alla generazione complessa di testo-in-immagine, ogni passaggio è regolabile per soddisfare le tue esigenze.

Alta Efficienza
SeaArt ottimizza i processi di creazione di arte IA. Approfitta di tempi di rendering più veloci e di minori ostacoli tecnici. Crea immagini sorprendenti rapidamente.


Migliaia di Workflow per la Creazione di Arte IA
Sblocca la tua visione artistica con il SeaArt Workflow. Accedi a migliaia di workflow preimpostati per generare arte IA senza sforzo in formati come testo-in-immagine, immagine-in-immagine e immagine-in-video. Questi workflow si integrano con potenti modelli IA come Flux, SD 3.5 e altre opzioni popolari, incluso ControlNet, offrendoti la flessibilità di creare immagini sorprendenti in base alle tue preferenze.

Controllo Completo con Workflow Personalizzabili
Con SeaArt Workflow, hai il pieno controllo sul tuo processo di generazione. Offriamo potenti opzioni di personalizzazione che ti permettono di adattare i workflow alle tue esigenze specifiche. Regola i parametri, cambia modelli IA e perfeziona le impostazioni per assicurarti che il risultato finale rispecchi la tua visione.
Domande Frequenti

Cos'è il ComfyUI Workflow?

Che tipo di arte IA posso generare con i workflow?
Questi workflow ti permettono di creare facilmente una vasta gamma di arte IA, tra cui ritratti realistici, paesaggi fantastici, personaggi anime e creazioni astratte. Puoi facilmente creare testo-in-immagine, immagine-in-immagine, e immagine-in-video, oltre a applicare trasferimenti di stile e persino generare modelli 3D.
Il ComfyUI Workflow è adatto ai principianti?
Sì! Con la nostra interfaccia intuitiva drag-and-drop e anteprime in tempo reale, il Workflow di SeaArt è accessibile sia ai principianti che agli utenti avanzati, rendendo facile la creazione di arte IA.
Posso personalizzare il mio workflow?
Sì. SeaArt AI offre varie impostazioni personalizzabili che ti permettono di configurare il tuo workflow in base alle esigenze specifiche del tuo progetto.