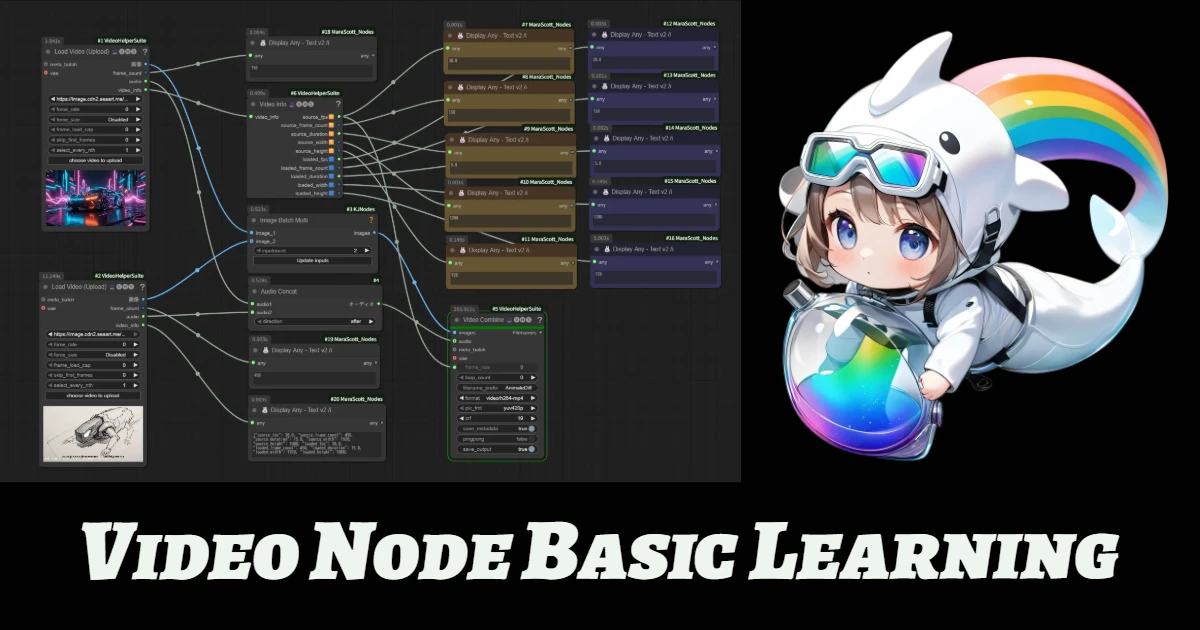
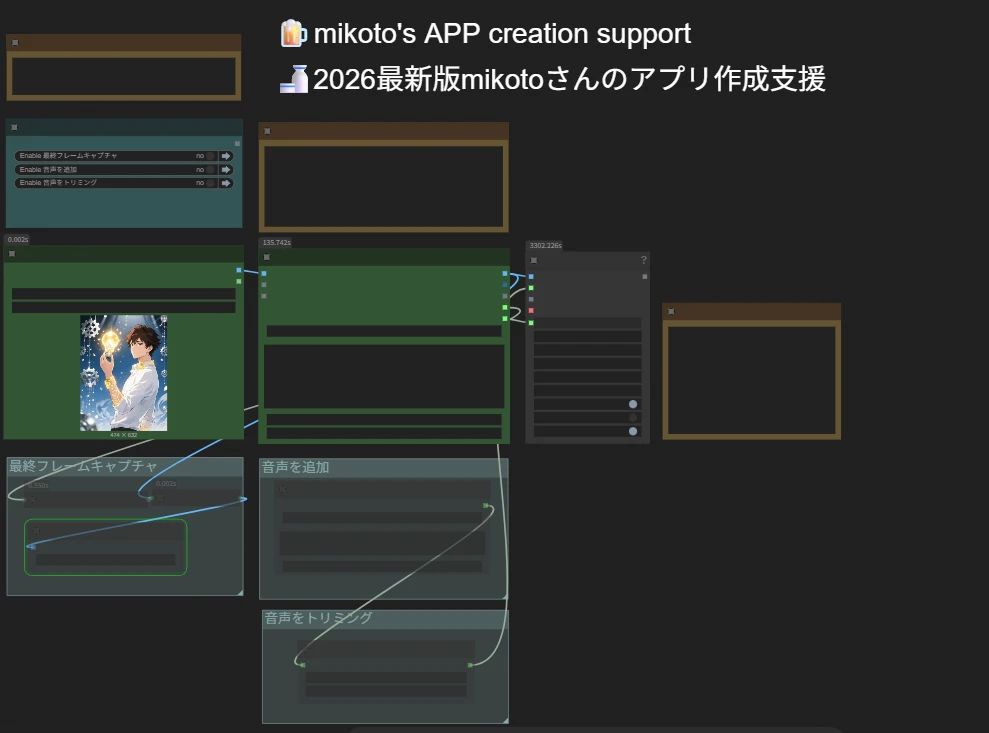
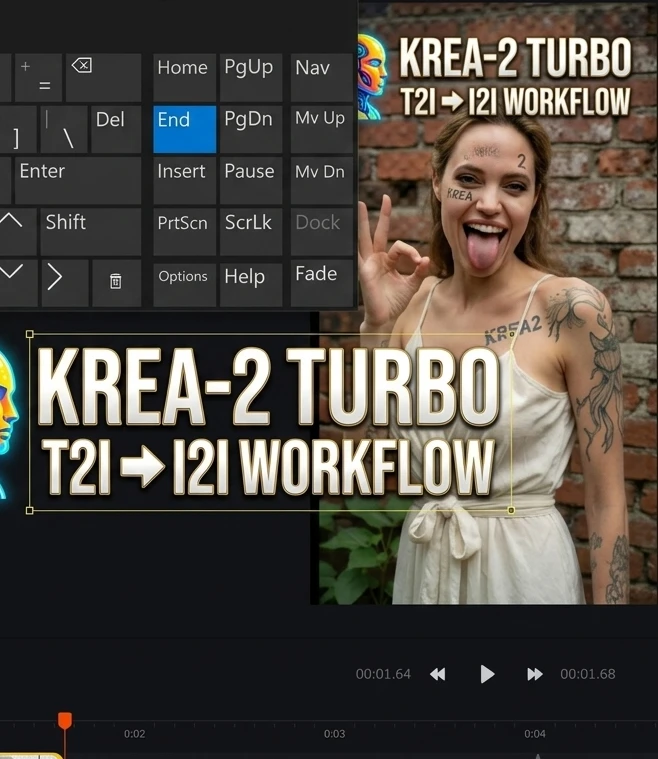
おすすめ
--
5.0
4.5
4.8
4.6
4.9
4.4
4.1
4.7
SeaArtのAIアート生成ワークフローを使って、創作の過程をよりスムーズにしましょう。アーティスト、デザイナー、クリエイターの多様なニーズに応えるよう設計されています。AI画像からAI動画まで、SeaArt AIはあなたの芸術的なビジョンを実現するために必要なすべてを提供します。
シンプルなインターフェース
SeaArt AIは、ワークフローの設定が簡単にできる直感的なインターフェースを提供しています。コーディングの知識がなくても、誰でも使えるように設計されています。
カスタマイズ可能なワークフロー
自分好みのワークフローをデザインしましょう。高度なLoRAトレーニングから詳細なテキストから画像生成まで、すべてのステップを調整して、あなたのニーズに合わせることができます。
高い効率性
SeaArtはAIアート制作のプロセスを最適化できます。より高速なレンダリングタイムと少ない技術的ハードルで、美しいビジュアルを迅速に作成できます。
SeaArtのワークフローであなたの芸術ビジョンを解き放ちましょう。テキストから画像、画像から画像、そして画像から動画など、様々な形式のAIアートを簡単に生成できる数千のプリセットワークフローにアクセスできます。これらのワークフローはFlux、SD 3.5などの強力なAIモデルやControlNetなどの人気オプションと統合されており、あなたの好みに合わせた素晴らしいビジュアルを作成する柔軟性を提供します。
SeaArtのワークフローを使えば、生成プロセスを完全にコントロールできます。強力なカスタマイズオプションを提供しており、ワークフローをあなたの特定のニーズに合わせて調整できます。パラメータを調整し、AIモデルを変更し、設定を微調整して、最終的な出力があなたのビジョンに合致するようにします。
ComfyUIワークフローとは?
SeaArt AIのワークフローは、単なるテキストプロンプトを超えた革新的なツールです。従来のAIアート生成器とは異なり、SeaArtは視覚的なワークフローシステムを提供し、カスタムワークフローを構築して、画像や動画の生成プロセスを細かく制御することができます。
どのような種類のAIアートをワークフローで生成できますか?
これらのワークフローを使えば、リアルな肖像画、ファンタジーの風景、アニメキャラクター、抽象的な創作など、幅広いAIアートを簡単に作成できます。テキストから画像、画像から画像、画像から動画のほか、スタイル転送や3Dモデルの生成も手軽に行えます。
ComfyUIワークフローは初心者向けですか?
はい!ユーザーフレンドリーなドラッグ&ドロップインターフェースとリアルタイムプレビューを備えているため、SeaArtのワークフローは初心者から上級者まで誰でも簡単に使用できます。AIアートの制作がシンプルになります。
ワークフローをカスタマイズすることはできますか?
はい。SeaArt AIではさまざまなカスタマイズ設定が用意されており、特定のプロジェクトニーズに合わせてワークフローを設定することができます。